Personalized PageRank and its composability
We ended the post on PageRank1 by reaching the following final equation:
\[\mathbf{r}^{(t+1)} = \beta M \cdot \mathbf{r}^{(t)} + (1-\beta) \left[\frac{1}{N}\right]_N\]Where the random walker with probability \(\beta\) decides to follow any random link of a node and with probability \(1-\beta\) it teleports itself to another random node of the graph, we also see that this is equivalent to add to the standard PageRank formulation a vector of \(N\) evenly distributed probabilities.
Topic-Specific PageRank
However, we may want that the random walker does not teleport itself to any random node of the graph but to a specific set of nodes, for example the ones that are related to a specific topic. In this way we compute PageRank that is not generic, but it is related to a specific topic: we call this kind of PageRank Topic-Specific. Why we need to alterate the random teleport? For example to make the walker teleporting to a set of trusted pages, in order to combating the web spam (see the TrustRank2), or simply to give a PageRank to pages in relation to a particular topic.
The new formulation
In general, we express the teleport set, namely the nodes to which the walker teleports itself as the set \(S\). Suppose the following graph:
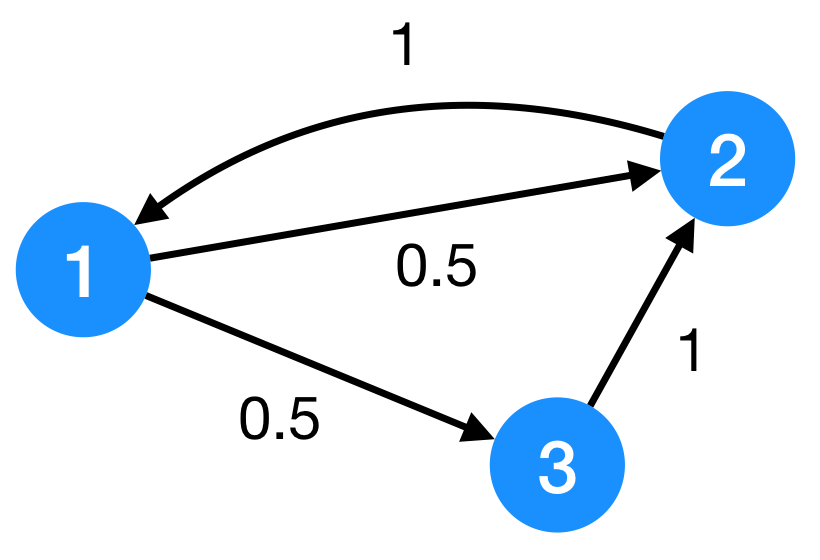
we can define, for example, a teleport set as:
\[S = \\{1,3\\}\]that we can translate to a personalization vector \(\mathbf{p}\)
\[p = \begin{pmatrix}0.5 \\\\ 0 \\\\ 0.5\end{pmatrix}\]Again, a stochastic vector3 which describes the probabilities of a random walker to teleport randomly to any node in the teleport set. You will agree with me that this kind of formulation is a generalization of the previous:
\[\mathbf{r}^{(t+1)} = \beta M \cdot \mathbf{r}^{(t)} + (1-\beta) \mathbf{p}\]since the standard PageRank is a Topic-Specific PageRank with a teleport set equal to all the nodes and with the teleport probability evenly distributed to all the nodes.
Example
Let’s see a SageMath 4 concrete example for the graph in the figure:
# Number of the nodes
n_nodes = 3
# Transition probabilities matrix
M = matrix([[0,1,0],[0.5,0,1],[0.5,0,0]])
b = 0.9
# Personalization vector
p = vector([0.5,0,0.5])
# Init the rank vector with evenly distributed probabilities
r = vector([1/n_nodes for i in range(n_nodes)])
for i in range(1000):
r = (b*M)*r + (1-b)*p
print("r = " + str(r))
It replies with: r = (0.392624728850325, 0.380694143167028, 0.226681127982646)
Dead ends? No problem
What if we had dead ends in the graph? As we did with the standard PageRank1 we have that the dead ends leak probability since they have no out link they do not take the \(\beta\) probability. So either we can manually make that we sum to every dead end column the \(\mathbf{p}\) vector, or we divide the algorithm in the following two steps:
-
Step 1: compute the standard PageRank
\[\mathbf{r}^{(t+1)} = \beta M \cdot \mathbf{r}^{(t)}\] -
Step 2: redistribute the leaked probability
\[\mathbf{r}^{(t+1)} = \mathbf{r}^{(t+1)} + (1 - \beta) \cdot \left(1 - \sum_i r^{(t+1)}_i\right) \mathbf{p}\]
Example
Here’s a running example with SageMath4:
# Number of the nodes
n_nodes = 3
# Transition probabilities matrix
M = matrix([[0,1,0],[0.5,0,1],[0.5,0,0]])
b = 0.9
# Personalization vector
p = vector([0.5,0,0.5])
# Init the rank vector with evenly distributed probabilities
r = vector([1/n_nodes for i in range(n_nodes)])
for i in range(1000):
# Step 1
r = (b*M)*r
# Step 2 - distribute the remaining probability
r = r + (1 - sum(r)) * p
print("r = " + str(r))
It replies with: r = (0.392624728850325, 0.380694143167028, 0.226681127982646)
Composability
Suppose now that we have personalization vector \(\mathbf{p}\) for \(k\) different topics and we want to build a final personalization vector for a specific user that has particular preferences for every topic. From the equation:
\[\mathbf{r}^{(t+1)} = \beta M \cdot \mathbf{r}^{(t)} + (1-\beta) \mathbf{p}\]since \(\mathbf{p}\) is a stochastic vector (its coordinates sums to 1) we can also obtain it from a composition of multiple topics. I think that showing a concrete example now is the best way of approaching to this topic.
Suppose that we have the personalization vector of 2 topics in general: cars and bikes. We have two stochastic vectors of \(N\) dimensions (where \(N\) is always the number of nodes):
- \(\mathbf{q}_{\textrm{cars}} = \begin{pmatrix}0.2 \\ 0 \\0.8\end{pmatrix}\) is the personalization vector that is specific for the cars topic;
- \(\mathbf{q}_{\textrm{bikes}} = \begin{pmatrix}0 \\ 0.7 \\0.3\end{pmatrix}\) it the personalization vector for the bikes topic.
Suppose now that we now want to compute a personalized PageRank for a user. For doing this it’s sufficient to understand how much the user likes cars and bikes, and compose a final personalization vector as composition of the cars and bikes vectors, weighted on the user addiction. Suppose that the user likes, by having normalized the values, \(0.30\) bikes and \(0.70\) cars, then we compose the vector \(\mathbf{p}\) as follows:
\[\mathbf{p} = 0.70 \cdot \mathbf{q}\_{\textrm{cars}} + 0.30 \cdot \mathbf{q}\_{\textrm{bikes}}\]It’s easy to prove that \(\mathbf{p}\) is still a stochastic vector. So in general, given a column stochastic vector \(\mathbf{s}\) of \(k\) topics coefficients, in this case:
\[\mathbf{s} = \begin{pmatrix}0.7 \\\\ 0.3\end{pmatrix}\]and a general matrix \(Q\) that is \(n\times k\) and contains all the personalization vectors for all the topics, in this case, for example:
\[\mathbf{Q} = \begin{pmatrix} \mathbf{q}\_{\textrm{cars}} & \mathbf{q}\_{\textrm{bikes}} \end{pmatrix} = \begin{pmatrix} 0.2 & 0 \\\\ 0 & 0.7 \\\\ 0.8 & 0.3 \end{pmatrix}\]it follows that the final formula for personalized PageRank is:
\[\mathbf{r}^{(t+1)} = \beta M \cdot \mathbf{r}^{(t)} + (1-\beta) Q \cdot \mathbf{s}\]Example
Let’s see the same example in SageMath4:
# Number of the nodes
n_nodes = 3
# Transition probabilities matrix
M = matrix([[0,0,1],[0.5,0,0],[0.5,1,0]])
b = 0.9
# Personalization vector for cars and bikes
P = matrix([[0.2, 0],[0, 0.7],[0.8, 0.3]])
# Vector of user likes for cars and bikes
s = vector([0.7, 0.3])
# Init the rank vector with evenly distributed probabilities
r = vector([1/n_nodes for i in range(n_nodes)])
for i in range(1000):
r = (b*M)*r + (1-b)*P*s
print("r = " + str(r))
It replies with: r = (0.388329718004339, 0.195748373101952, 0.415921908893709)
-
The TrustRank is explained in the book Mining of Massive Datasets, Jure Leskovec, Anand Rajaraman, Jeff Ullman ↩
-
There’s no need that the probabilities must be evenly distributed to all the nodes in the teleport set, we can also specify arbitrary ones ↩
-
You can find all my material as Sage maths notebooks, summaries and questions on my repo, see the
README.md↩ ↩2 ↩3