PageRank: origini ed esempi pratici
Ho voluto scrivere un post per chiarire in modo semplice ed elegante la caratteristica peculiare di un PageRank specifico per argomento, ovvero quella di essere componibile rispetto ai vettori di personalizzazione. Tuttavia ho deciso di partire dall’inizio, dividendo il percorso in due parti: la prima è questa, dove vedremo motivazioni e formulazione generale del PageRank, mentre nella seconda tratterò le varianti personalizzate del PageRank.
Che cos’è il PageRank
Supponiamo di voler classificare le pagine web assegnando loro un punteggio che rifletta il loro grado di autorità e popolarità. La proprietà fondamentale del grafo del web da considerare sono i link. I link sono una misura di popolarità: teoricamente, se metti un link a un’altra pagina web significa che la consideri autorevole (come nel caso di link a Wikipedia, libri o fonti citazionali). Inoltre, è raro che una pagina spam colleghi una buona pagina; in generale, le buone pagine linkano altre buone pagine, mentre le pagine spam linkano altre pagine spam. Questa è la natura dei link.
Il camminatore casuale
Come possiamo usare i link per valutare le pagine? Non basta contarli, perché si potrebbero facilmente creare pagine spam con tanti link in entrata e uscita. L’idea brillante del PageRank è di considerare la somma pesata dei link in entrata, pesati però in base al rank della pagina da cui provengono. In generale, per una pagina $j$, con link da una pagina $i$ di grado uscente $d_i$, il punteggio di $j$ può essere espresso come:
\[r_j = \sum_{i\rightarrow j} \frac{r_i}{d_i}\]Il rank della pagina $i$ viene quindi suddiviso equamente tra tutti i suoi link in uscita. Possiamo interpretare questa equazione immaginando un camminatore casuale: un’entità che si muove sul nostro grafo scegliendo ogni volta un link casuale dalla pagina in cui si trova. La probabilità di scegliere un link è distribuita equamente tra tutti i collegamenti disponibili. Noti la somiglianza? Anche nel PageRank il punteggio era distribuito uniformemente sui link uscenti.
Questo comportamento può essere modellato con una catena di Markov, un modello statistico composto da $N$ stati (i nodi del grafo). La proprietà chiave è la possibilità di descrivere in forma elegante tutte le scelte del camminatore tramite una matrice di transizione colonna-stocastica $M$. Ogni colonna rappresenta lo stato corrente (un nodo), ogni riga rappresenta il prossimo nodo visitabile. L’elemento $M_{ij}$ indica la probabilità che il prossim nodo sia $i$ dato che il camminatore si trova su $j$. Di conseguenza la somma di ogni colonna è pari a 1.
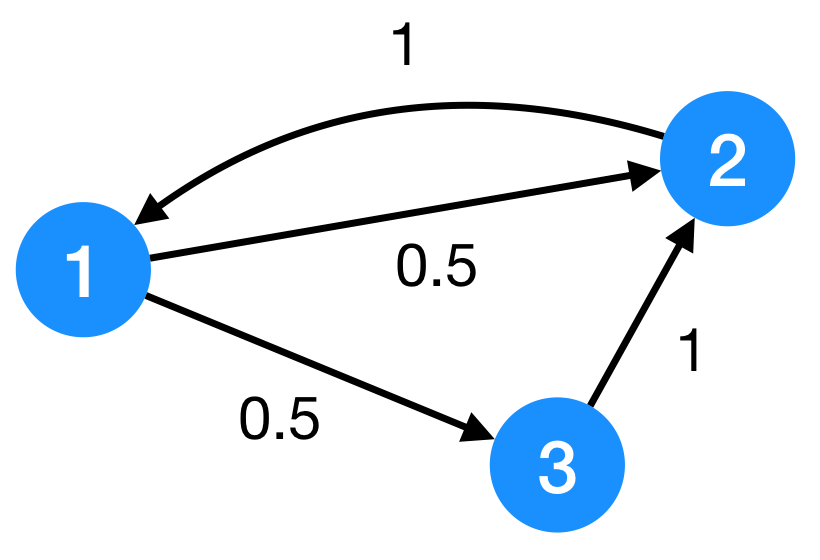
Per il grafo in figura la matrice di transizione è:
\[M = \begin{pmatrix} 0 & 1 & 0 \\ 0.5 & 0 & 1 \\ 0.5 & 0 & 0 \end{pmatrix}\]In generale, possiamo riscriverla come:
\[M = \begin{pmatrix} 0 & \frac{1}{d_2} & 0 \\ \frac{1}{d_1} & 0 & \frac{1}{d_3} \\ \frac{1}{d_1} & 0 & 0 \end{pmatrix}\]Se $\mathbf{r}$ è il vettore colonna con i rank di tutte le pagine, otteniamo:
\[\mathbf{r}^{(t+1)} = M \cdot \mathbf{r}^{(t)}\]Metodo delle potenze
Il calcolo del PageRank avviene iterando la stessa equazione sul vettore $\mathbf{r}$, da cui il nome power method. Si parte da:
\[\mathbf{r}^{(0)} = \left[ \frac{1}{N} \right]_N\]cioè un vettore uniforme. Con le iterazioni il vettore converge a una distribuzione stazionaria, detta anche tasso di visita a lungo termine.
Esempio:
- Passo 0: $\mathbf{r}^{(1)} = M \cdot \mathbf{r}^{(0)}$
- Passo 1: $\mathbf{r}^{(2)} = M \cdot \mathbf{r}^{(1)}$
- … fino a convergenza.
Patologie
Due problemi principali nei grafi reali:
- Spider traps: gruppi di pagine che si linkano tra loro senza uscire. Trappole per il camminatore.
- Dead ends: nodi senza link in uscita, che rompono la matrice colonna-stocastica.
Per garantire la convergenza, la catena di Markov deve essere ergodica (irriducibile e aperiodica).
La soluzione
Si introduce la probabilità di teletrasporto:
- con probabilità $\beta$, segue un link casuale;
- con probabilità $1-\beta$, salta in una pagina scelta a caso.
La nuova equazione per una pagina $j$ diventa:
\[r_j = \beta \sum_{i\rightarrow j} \frac{r_i}{d_i} + (1-\beta)\frac{1}{N}\]In forma compatta:
\[\mathbf{r}^{(t+1)} = \beta M \cdot \mathbf{r}^{(t)} + (1-\beta)\left[\frac{1}{N}\right]_N\]